July 19, 2025 - Daily Drill¶
🎯 Daily Goals¶
- Review Anki Deck
- Lumosity training
- Finish AI Engineering Agent Chapter
- Leetcode
- Developing pdf-chat
📝 What I learned:¶
Leetcode problem¶
Thinking Process¶
I saw the limitation of the string length is at most 8 and I jumped right to the brutal force. The main idea is to iterate through all possible string with length 2n and check if it is well-formed. To generate, a combination of parenthesis string with length 2n. I iterate through number 2^(2n - 1)^ to 2(2n) - 1 and mapped the binary bits 1 to '(', 0 to ')'. Or we can use BFS to generate all possible combination. Then we just check if the string is a valid one and append it to the output array. In hindsight, using backtrack can prune the search tree easily. Instead of using a BFS, we can do a DFS and check if the current string is a valid one by checking if its left parenthesis count is smaller or equal to n and if the left parenthesis is not less than the right parenthesis count.
Useful code snippet¶
Check if a string is well-formed parentheses.
def check_parentheses(s: str) -> bool:
left_cnt = 1
for c in s:
if c == "(":
left_cnt += 1
else:
left_cnt -= 1
if left_cnt < 0:
return False
return True
Generate all possible combiniation with bfs
from collections import deque
def generate_all_comb(n: int) -> list[str]:
queue = deque([""])
ans = []
while queue:
cur_str = queue.popleft()
if len(cur_str) == n:
ans.append(cur_str)
continue
queue.append(cur_str + "(")
queue.append(cur_str + ")")
return ans
Check if a number n's xth bit is 1
'n >> (x - 1) & 1 == 1'
Complexity Analysis¶
Denote the length of the string as n
For brutal force: Time Complexity: O(22n*n)
Space Complexity: O(22n*n)
Reasoning: We iterate through all of the combination of parenthesis string with length 2n that would be 22n and for each string we need O(n) time to check if it is valid thus. O(22n*n) for time. For the space, the queue would be largest when it reaches the bottom. It would have 22n string in it each with length 2n. Thus O(22nn) for space complexity.
Key Takeaway¶
- How to check valid parenthesis string
- How to all possible combination through BFS and DFS
AI Engineer Book¶
Last time we studied the planning part of the AI agent workflow. So far the system has three components or agents: one to generate plan, one to evaluate plan and another to execute plan.
How to generate a plan¶
First, we need to know that the easiest way to turn a FM into a planner is through prompt engineering. Here is a sample prompt that does that trick:
SYSTEM PROMPT
Propose a plan to solve the task. You have access to 5 actions:
get_today_date()
fetch_top_products(start_date, end_date, num_products)
fetch_product_info(product_name)
generate_query(task_history, tool_output)
generate_response(query)
The plan must be a sequence of valid actions.
Examples
Task: "Tell me about Fruity Fedora"
Plan: [fetch_product_info, generate_query, generate_response]
Task: "What was the best selling product last week?"
Plan: [fetch_top_products, generate_query, generate_response]
Hallucination is always the biggest enemy of AI application. Here hallucination might happen when the user prompt or task is not clear enough. For example, we might as about "What is the average price of the top products?". The prompt here does not mention any of the parameter required for the function fetch_top_products. Do we want all of the top products or just 5? Do we want the top products within this week or month? Since we did not provide these information, the model is going to predict it by itself. And that's where hallucination comes.
Some techniques to solve this involves:
-
Make it easier for AI to use the tools
- Write a better system prompt with more examples.
- Give better descriptions of the tools and their parameters so that the model understands them better.
- Rewrite the functions themselves to make them simpler, such as refactoring a complex function into two simpler functions.
-
Improve the model
- Use a stronger model. In general, stronger models are better at planning.
- Finetune a model for plan generation.
Function calling¶
Tools are often created as a function for models to call. Thus using tools is called "function calling".
Create function calling involves two steps in general:
- Create a tool inventory (i.e. define a list of function with its function name, parameters and documentation)
- Specify what tools the agent can use (This sounds a bit weird, since we can give the model access to all tools available and let itself decide. However, letting people to choose the tools set would help alliveate the hallucination problem)
An example of function calling:

Debug function calling
When working with agent always tell the system to output the arguments they use
Plan granularity¶
When creating a plan there is a trade-off between plan granularity and execution. More detailed or granular a plan is, the easier to execution. However, a granular plan is both hard to generate and to maintain. In the previous prompt example, the model would generate a plan in the format of a list of functions which is very detailed. The trade-off is if the function name or parameter changes, you have to update the examples and prompt as well. Also, your planner won't work on different APIs. Even worse, if you fine-tuned your model for these tools, you need to fine-tune it again for new functions. In general, it would be better to tell the models to generate plans in natural languages. Thus, it is not too hard to execute but also easier to maintain.
Complex Plan¶
Complex plan refers to plans that is not sequential. You can add control flow, loop into it and even add parallel workflow. The order of which actions is executed is called control flow.
Four types of control flow: Sequential, If statement, Parallel, For Loop
Let's clarify on the Parallel control flow a bit. One example could be loop for the price of top 100 best selling product. The workflow should be: first find all top 100 best selling product. Then retrieve the price of each of them. Parallel control workflow can optimize the process of getting the price of each product by creating subtasks or subagent to retrieve the price concurrently. Usually, you can apply this pattern when you need to first fetch a bunch of result and perform some action on each of them. I think the deep research feature of these popular models uses parallel control flow. Models would create subagent to fetch different websites simulaneously to redunce latency.
Reflection and error correction:¶
When to reflect?
- Validate is a query is feasible
- Check if the generated plan is good enough
- Evaluate each step during the workflow execution to make sure it is on the right track
- Determine if the final output satisfied the user's need
To achieve reflection, we can add an extra model as a scorer or use a self-reflecting prompt.
One of the famous example is ReAct framework. The framework tells the model to interleave reasoning and action where reasoning is essentially planning and reflection. The agents is told to reason first, then take action and finally analyze its observation. While the initial ReAct framework is just a prompt engineering that allows a single model to think and act in multiple steps. In our multi-agent system, each task could be delegated to each agent.
Pros and Cons of reflection
Reflection is comparatively easy to implement and have surprisingly good performance improvement. Nevertheless, it would introduce more latency and costs. Since thoughts, observation and actions are expensive to generate. To make sure the model would generate in the format of thought, action and reflection. Model creators usually need to use a plenty of examples in the prompt. This would also reduces the context space available for other information.
Tool selection¶
To select the best tool set, it is mostly trials and errors. Here are some apporaches that might help you find best tool set
- Ablation test
- Compare model performance with different tool set
- Look for tools that agent frequently make mistake on
- Plot the distirbution of tool calls to see what tools are most used and what are least used
Agent Failure Modes and Evaluation¶
Planning Failure
Planning failure is often associated with tool use common errors are:
- Invalid tool
- Valid tool, invalid parameters
- Valid tool, incorrect parameter values
Another type is goal failure: the agent fails to achieve the goal. The plan might fail to solve a task or fail to solve under the contraint given in the prompt.
A special type of plan failure is caused by error in the reflection. Remember how we need to use reflect to check if a plan is valid or not. If the reflection itself is problematic, the agent migth be convinced that it has accomplished a goal while it hasn't.
To properly evaluate what is causing the plan failure we can use the following metric:
Create a planning dataset where each example is a tuple (task, tool inventory). For each task, use the agent to generate a K number of plans. Compute the following metrics:
- Out of all generated plans, how many are valid?
- For a given task, how many plans does the agent have to generate, on average, to get a valid plan?
- Out of all tool calls, how many are valid?
- How often are invalid tools called?
- How often are valid tools called with invalid parameters?
- How often are valid tools called with incorrect parameter values?
Analyze the pattern and hypothesize what is causing the problem.
Tool Failure¶
Tool failures only happen when a correct tool is choosen by the plan and yet the output is wrong. From here we can easily see that there are two places things could go wrong. One is the tool itself, the other is transaltor that translate the high level plan into executable commands.
To debug, we need to test each tool independently and make sure the model have resource or credential to use that tool. For translator we might mimic how we evaluate the planner. We can test the translator with a list high level plans and check its output.
Efficiency¶
To check efficiency, we need to know the following:
- How many steps does the agent need, on average, to complete a task?
- How much does the agent cost, on average, to complete a task?
- How long does each action typically take? Are there any actions that are especially time-consuming or expensive?
Memory¶
Memory is essential for model to retain and utilize informaion and is more useful for knowledge-rich application like RAG and agents.
There are three types of memory mechanism:
- Internal knowledge (the knowledge captured by model parameters)
- Short-term memory (Model context window)
- Long-term memory (extra datasource model have access to, RAG system basically)
Some pros for adding external memory system to AI models:
- Prevent system context overflow
- Smooth UX between session
- Ensure answer consistency (It could remember the answer from last time)
- Maintain data structural integrity (text data is unstructured, if we use information from a external table things would be different)
Memory system consists of two functionality:
- Memory management (decides on which memory should go into long-term and which should be in short-term)
- Memory retrieval (fetch info from long-term memory)
Memory retrieval is similar to RAG system so we only illustrate how memory management work. Essentially, memory management only have two operations: add and delete. Knowing which memory to add and which memory to delete is the key.
Context Window
For each query, if the responding to the query requires external knowledge, the model would reserve some part of the context windowf for retrieved external knowledge. Knowing that context window is shared by both short-term and long-term memory helps you form an accurate mental model of it. Also, when the short-term memory overflows due to limited context window. It is a common practice to temporarily store them in the long-term memory.
An easiest way of managing memory is FIFO order. We delete the outdated memory for fresh ones. This is based on the assumption that early messages are less relevant to the current conversation which is not necessarily correct and in some cases severely wrong. More sophisticated way is to compress the memory or removing redundancy. A good approach is to make a summerization over the information. Look for Memory Management through Summarization for more detail. There is also a reflection approach.
MCP¶
MCP is an open source protocol that standardized how model can connect to external resources which includes but not limits to database, code repo and APIs. To be more specific, it defined a structured interface for:
- Tool calling
- Schema based input and output
- Authentication and access control
- Context-aware invoation
The main architecture:
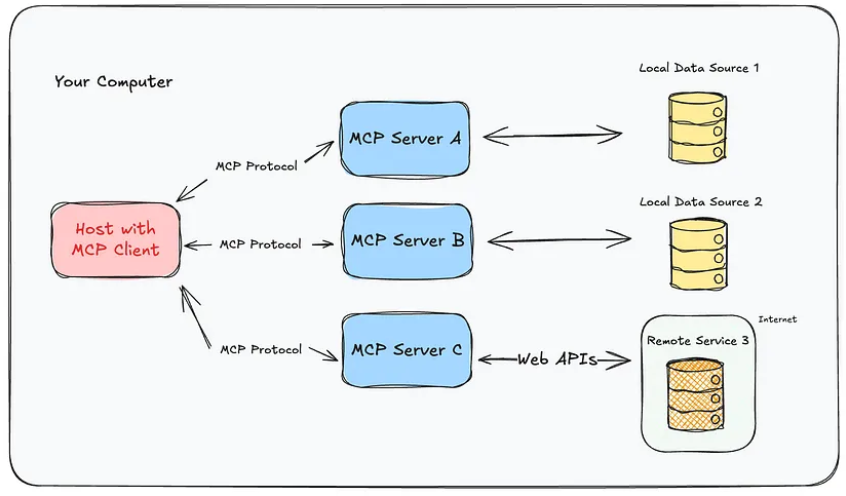
You can see that MCP has two main parts: **MCP server and MCP clients"
MCP Server can be considered as a smart adapter for a tool or an app. It is managed by whoever is providing the tools and application. For example, github can create MCP server that allows AI to create a PR and resolve and issue. youtube can create an MCP server that allows AI to subscribe to channels and download videos.
MCP server components and its purpose:
| Component | Purpose |
|---|---|
| Tool schemas | Define tool name, description, input/output schema (often in OpenAPI/JSON Schema) |
| Invocation endpoint | A standard HTTP endpoint that executes the tool with provided arguments |
| Manifest/registry | A file or endpoint that lists all available tools and their specs |
| Authentication | Handles access control for who can call the tool (e.g. API keys, OAuth) |
| Metadata | Describes version, owner, categories, etc. |
MCP client is simply a software component or a layer that connects to MCP server reads the MCP tool list, registers them to the AI and handles tool calling when needed.
For a more detailed version:
| Step | Function |
|---|---|
| 1. Discovery | Fetches the list of tools from a remote MCP server (e.g. via a manifest endpoint or OpenAPI spec) |
| 2. Schema Parsing | Parses each tool’s input/output schema and description (JSON Schema or OpenAPI) |
| 3. Expose to Model | Formats the tools into a format the model understands (e.g., OpenAI function spec, JSON tool-call input) |
| 4. User Query Handling | Sends the user query and available tool specs to the LLM |
| 5. Tool Selection & Arguments | Lets the LLM choose a tool and generate arguments |
| 6. Invoke Tool | Makes an actual HTTP call to the MCP server’s execution endpoint |
| 7. Return Result | Sends the tool’s response back to the model as an observation for further reasoning or final answer |
You can find MCP client in the AI application like Microsoft Copilot, Cursor etc.