July 17, 2025 - AI Engineer RAG¶
🎯 Daily Goals¶
- Review Anki Deck
- Lumosity training
- Finished AI Engineering RAG Chapter
📝 What I learned:¶
AI Engineer Book¶
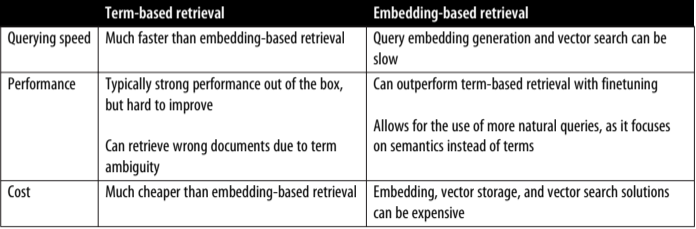
The comparison between term-based retrieval and embedding-based retrieval¶
Metrics for evaluation¶
For retrieved documents only - Context Precision: The percentage of relevant documents among all retrieved ones - Context Recall: The percentage of retrieved documents among all relevant ones
Document ranking
This expects the most important documents should be retrieved first
- NDCG (normalized discounted cumulative gain)
- MAP (Mean Average Precision)
- MRR (Mean Reciprocal Rank)
Embedding
We should also evaluate the retriever with the model as a whole. The evaluation would be talked about in the future chapters
Note
The most time consuming part of a RAG system is actually the output generation. The embedding generation and vector search is actually minimal when compared to it.
Design choice of retrieval system¶
Mainly, we consider two parts, indexing cost and querying quality.
To improve query quality, we use more detailed index which takes much more time and memory to create and thus getting higher query quality. One example of index of this kind is: HNSW
To reduce index cost, we can use simpler index like LSH. This is easier to build and yet results in slower and less accurate queries.
We also have control over the ANN algorithm used during retrieval. Check the performance for each of them here.
Three aspects of RAG evaluation:¶
- Retrieval Quality
- Context precision, recall, query speed and accuracy, indexing efficiency
- Embedding (For embedding-based retrieval only)
- MTEB
- RAG output
- Evaluate LLM output